
SQL là công cụ quan trọng để truy cập, sửa đổi và thao tác dữ liệu. Nhưng liệu chúng ta có thể tận dụng AI vào truy vấn dữ liệu SQL để viết và tối ưu hóa truy vấn SQL không? Đây là lúc ChatGPT của OpenAI xuất hiện, một mô hình trí tuệ nhân tạo LLM* (large language model) có khả năng hỗ trợ viết các truy vấn SQL. Trong bài viết này, chúng ta sẽ đi sâu vào cách mà LLM có thể cách mạng hóa quá trình viết SQL.
Tiềm năng của AI vào truy vấn dữ liệu SQL – ChatGPT trong việc tạo truy vấn
Với sự xuất hiện của ChatGPT của OpenAI, quá trình viết SQL cổ điển đang được định hình lại. LLM* cung cấp một phương pháp hiện đại để tạo ra các truy vấn SQL, điều quan trọng là hiểu rõ các ưu điểm và hạn chế của công cụ để sử dụng hiệu quả. Hãy đi vào một số ưu và nhược điểm của việc sử dụng GPT-4 để viết các truy vấn SQL.
Ưu điểm:
- Tốc độ: Ứng dụng AI vào truy vấn dữ liệu SQL như ChatGPT có thể tạo ra các truy vấn SQL nhanh chóng, giúp giảm thiểu thời gian.
- Công cụ học tập: Người mới có thể tận dụng chatbot như một nguồn tài nguyên học hữu ích, cung cấp các ví dụ và xác minh cấu trúc truy vấn.
- Cơ sở kiến thức rộng lớn: GPT-4 có hiểu biết về một loạt các functions, operations và best practices* (những kiến thức rút được dựa theo kinh nghiệm của những người đi trước trong ngành, mà chúng ta nên biết và làm theo) của SQL.
- Sự nhất quán: Khác với con người, AI không mệt mỏi hoặc mất tập trung, đảm bảo một mức độ chất lượng đầu ra nhất quán.
- Khả năng thích ứng: bạn cũng có thể chỉ định các loại khác nhau (ví dụ: MySQL, PostgreSQL) để có đầu ra truy vấn được đa dạng.
Nhược điểm của AI vào truy vấn dữ liệu SQL
- Thiếu ngữ cảnh sâu sắc: Mặc dù GPT-4 có thể xử lý thông tin được cung cấp, nhưng nó không có hiểu biết sâu sắc về sự phức tạp của một cơ sở dữ liệu cụ thể hoặc ngữ cảnh kinh doanh rộng lớn hơn.
- Yêu cầu Hướng dẫn Cụ thể: Các yêu cầu mơ hồ hoặc khái quát có thể dẫn đến đầu ra chung chung và không tối ưu. Yêu cầu rõ ràng và cụ thể là quan trọng để đạt được sự chính xác.
- Không Thay Thế Kiến thức Chuyên môn: Đối với các nhiệm vụ cực kỳ phức tạp, tinh tế hoặc quan trọng về hiệu suất, kinh nghiệm và trực giác của một chuyên gia cơ sở dữ liệu đã có sẵn vẫn không thể thay thế được.
- Lo ngại về Bảo mật: Phụ thuộc nặng nề vào các nền tảng bên ngoài để tạo truy vấn SQL có thể gây ra các rủi ro bảo mật tiềm ẩn, đặc biệt là nếu thông tin lược đồ nhạy cảm hoặc dữ liệu được chia sẻ.
- Khả năng hiểu sai: Nếu yêu cầu của người dùng không rõ ràng, AI vào truy vấn dữ liệu SQL như ChatGPT có thể tạo ra một truy vấn, mặc dù cú pháp chính xác, nhưng có thể không đạt được kết quả được dự kiến.
Tóm lại, tuy ChatGPT mang lại một công cụ đột phá cho việc viết SQL và cung cấp nhiều ưu điểm, việc tiếp cận nó cần hiểu rõ các hạn chế sử dụng của nó, đặc biệt là trong cách ứng dụng vào chuyên môn.
So sánh ChatGPT và các nhà phân tích dữ liệu con người trong việc viết SQL
ChatGPT có thể được so sánh với một data analyst cấp entry-level, nhưng không có sự hiểu biết tự nhiên về ngữ cảnh kinh doanh hoặc kiến thức kinh nghiệm từ làm việc trực tiếp với dữ liệu. Đối với những người mới, ChatGPT là một nguồn học quan trọng, giúp họ phát triển kỹ năng viết SQL và hiểu rõ best practice*.
Đối với các data analyst có kinh nghiệm, việc sử dụng ChatGPT giúp tiết kiệm thời gian và hỗ trợ trong việc xử lý công việc cơ bản, tạo thêm thời gian cho các phân tích phức tạp. Tóm lại, mặc dù không thể thay thế được sự chuyên môn của data analyst, ChatGPT đóng vai trò quan trọng trong việc tối ưu hóa quy trình và hướng dẫn người mới vào lĩnh vực này.
Các phương pháp tốt nhất với ChatGPT cho việc viết SQL
Cách cấu trúc một cuộc trò chuyện với ChatGPT để viết SQL
Các bước và phương pháp tốt nhất để đạt được kết quả viết SQL tối ưu với ChatGPT:
- Đơn giản hóa vấn đề: Giảm bài toán SQL của bạn xuống dưới dạng đơn giản nhất. Trích xuất các yêu cầu và loại bỏ bất kỳ chi tiết dư thừa nào.
- Cung cấp ngữ cảnh liên quan: Đặt rõ các bảng và cột, mối quan hệ giữa các bảng, loại cơ sở dữ liệu bạn đang sử dụng và dữ liệu mẫu nếu có thể.
- Rõ ràng về ràng buộc và đầu ra mong muốn: Xác định các bộ lọc mà bạn cần áp dụng, sắp xếp, tổng hợp và bất kỳ xem xét về hiệu suất nào như tránh quét toàn bộ bảng.
- Lặp lại truy vấn của bạn: Không có gì ngạc nhiên khi trả lời đầu tiên không hoàn hảo. Bạn nên mong đợi làm rõ ràng, yêu cầu điều chỉnh truy vấn và chạy truy vấn một vài lần trước khi đạt được điều bạn cần.
Ví dụ về việc ứng dụng AI vào truy vấn dữ liệu SQL
Để hiểu về khả năng của ChatGPT trong việc viết SQL, chúng tôi đã thử nghiệm nó với một số câu hỏi phổ biến mà các nhà phân tích SQL thường gặp. Tập data thử nghiệm được lấy từ một cửa hàng thương mại điện tử hư cấu.
Yêu cầu ChatGPT viết một truy vấn SQL select đơn giản
Nhiệm vụ đầu tiên của chúng tôi là yêu cầu một câu lệnh select đơn giản, không JOIN, aggregations hay functions khác. Đây là một nhiệm vụ rất đơn giản, và không có khả năng sử dụng nếu người dùng mới bắt đầu viết SQL. Hầu hết các trình soạn thảo SQL đều làm cho việc xem trước kết quả trong một bảng hoặc chọn tất cả các cột trong một bảng dễ dàng.
Bài toán đưa ra cho ChatGPT-4 là:
“Tôi cần một truy vấn SQL cho BigQuery lấy từ bảng ecommerce.products của tôi và trả về id, cost, name, brand, retail_price và sku. Truy vấn nên được lọc chỉ hiển thị bộ phận “Men” và danh mục “Swim”.”
Và ChatGPT-4 đã trả lời:
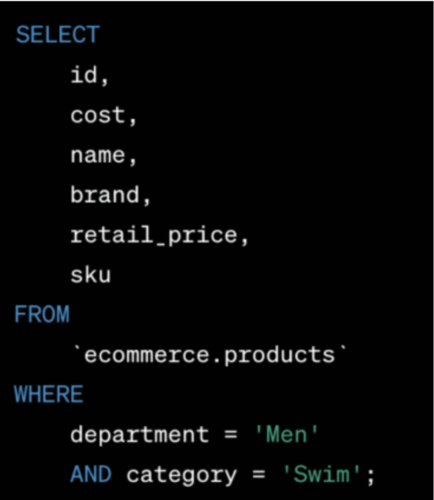
Phân tích: Truy vấn này rất đơn giản, và ChatGPT đã phản hồi phù hợp. Nó thậm chí còn biết thêm dấu ‘ ‘ vào tên bảng, điều này là điểm độc nhất cho BigQuery.”
Yêu cầu ChatGPT viết SQL JOIN và aggregations
Tương tự như câu trên. demo database có các foreign keys rất dễ nhận biết (orders.user_id JOIN với users.id, và các foreign keys khác cũng tương tự). Vì lý do đó, chúng tôi không nhận mạnh vào key của JOIN rõ ràng trong yêu cầu:
“Tôi cần một truy vấn SQL. Tên schema là ecommerce và các bảng là users và orders. Tôi muốn một output có từng tên của mỗi người dùng (users.name) và email, cùng với tổng số đơn hàng mà mỗi người dùng đã thực hiện và tổng số mặt hàng mà họ đã mua (orders.num_of_item). Bảng orders có một cột user_id. Tôi cũng cần lọc chỉ hiển thị các đơn hàng với trạng thái “Complete” và được tạo sau ngày 1/1/ 2020 trở đi. Sắp xếp kết quả theo tổng số đơn hàng từ cao nhất ở trên cùng đến thấp nhất ở dưới cùng.”
ChatGPT đã trả lời:
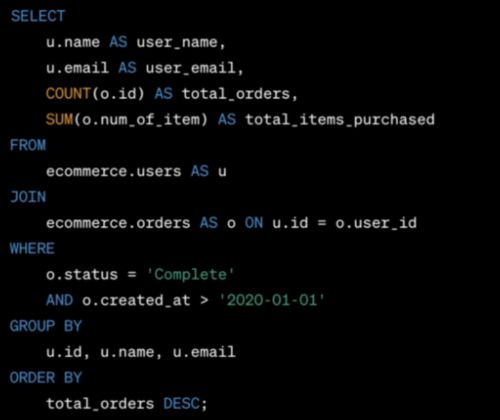
Nó thậm chí cung cấp một tóm tắt gọn gàng hơn về những gì truy vấn làm so với yêu cầu ban đầu tôi đã viết:
“Truy vấn này trước tiên JOIN hai bảng trên user ID, sau đó lọc dựa trên trạng thái đơn hàng và ngày tạo. Kết quả được nhóm theo ID người dùng, tên và email. Cuối cùng, nó sắp xếp kết quả đã tổng hợp dựa trên tổng số đơn hàng giảm dần.”
Phân tích: ChatGPT thực hiện nhiệm vụ này hoàn hảo trừ 1 chỗ. Yêu cầu của chúng tôi chứa một câu lệnh không rõ ràng, nhưng đó là chỗ mà một data analyst có thể nhận ra và sửa lại thay mặt cho người yêu cầu truy vấn. Chúng tôi nói “Tôi cũng cần lọc chỉ hiển thị các đơn hàng … được tạo sau ngày 1/1/2020 trở đi.” Câu lệnh WHERE sử dụng dấu “>” để loại trừ ngày 1/1/2020, nhưng yêu cầu ngụ ý sẽ sử dụng “>=” để bao gồm cả ngày 1 tháng 1 năm 2020.
ChatGPT đã biết cách JOIN hai bảng ngay cả khi không đề cập rõ từ khóa JOIN. Nó cũng sử dụng đúng hàm sum để tính tổng số mặt hàng đã đặt hàng.
Yêu cầu GPT-4 tạo ra các truy vấn SQL với các hàm
Để làm cho việc thú vị hơn một chút, chúng tôi không bắt đầu từ đầu lần này. Chúng tôi chỉ yêu cầu một câu hỏi bổ sung sau yêu cầu trước đó. Lần này, yêu cầu được viết một cách tự nhiên hơn và ít cụ thể hơn:
“Làm lại truy vấn ở trên, nhưng thêm một cột cho xếp hạng của mỗi khách hàng và phần trăm xếp hạng dựa trên tổng số đơn hàng. Truy vấn này dành cho BigQuery. Đối với 10 khách hàng hàng đầu, thêm street_address, city, state, và postal_code (từ bảng users) để chúng tôi có thể gửi giải thưởng cho họ.”
ChatGPT lại một lần nữa trả lời với một câu trả lời hoàn hảo như mong đợi.
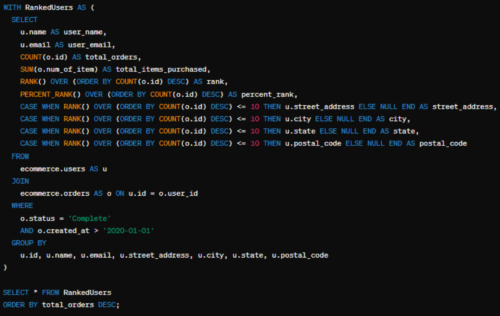
Truy vấn này trước tiên tạo một CTE (RankedUsers) để xếp hạng người dùng dựa trên số đơn hàng tổng cộng của họ. Nó sử dụng câu lệnh CASE để chỉ hiển thị chi tiết địa chỉ cho 10 khách hàng hàng đầu. Kết quả cuối cùng được sắp xếp theo số đơn hàng tổng cộng theo thứ tự giảm dần.
Trước khi chúng tôi phân tích câu trả lời này, chúng tôi đặt ra một thách thức lớn hơn và hỏi nó về một vấn đề mà một nhà phân tích kinh doanh thực sự có thể gặp phải:
“Kết quả của truy vấn đó đưa ra cho tôi 20 người chiến thắng vì 20 khách hàng hàng đầu đều có cùng số đơn hàng, bạn đề xuất tôi làm gì? Tôi chỉ có thể tặng 10 giải thưởng… làm thế nào tôi có thể điều chỉnh truy vấn để chỉ nhận được 10 người chiến thắng?”
Câu trả lời này cũng rất ấn tượng:
Nếu có nhiều Khách hàng có cùng số đơn hàng và chỉ muốn thưởng cho một số lượng giới hạn của họ, bạn có một số lựa chọn:
- Chọn 10 đầu tiên dựa trên Tiêu chí Khác: Bạn có thể sử dụng một tiêu chí bổ sung như ngày đặt hàng sớm nhất, tổng số tiền đã chi, hoặc một cột khác để phá vỡ sự cân bằng.
- Ngẫu nhiên từ các Khách hàng có cùng số đơn hàng: Nếu bạn muốn sử dụng một tiêu chí bổ sung để phá vỡ sự cân bằng, bạn có thể ngẫu nhiên chọn 10 người chiến thắng từ số lượng top Khách hàng có cùng số đơn hàng. Dưới đây là một cách tiếp cận sử dụng lựa chọn thứ hai, trong đó chúng tôi sẽ ngẫu nhiên chọn 10 người chiến thắng:
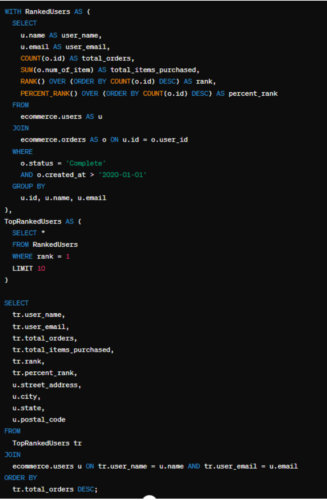
Truy vấn này trước tiên xếp hạng người dùng dựa trên tổng số đơn hàng của họ. Sau đó, nó sử dụng CTE TopRankedUsers để giới hạn số lượng người chiến thắng chỉ là 10 bằng cách chọn xếp hạng đầu tiên và giới hạn số hàng. Cuối cùng, nó tham gia lại bảng người dùng để lấy thông tin địa chỉ cho những người chiến thắng này.
Phân tích: Trong câu hỏi tiếp theo, chúng tôi cuối cùng đã thấy một sự sai sót trong các quyết định viết SQL của ChatGPT-4. Bạn có nhận thấy không? Nó đã sử dụng tên và email để tham gia bảng người dùng với chính nó thay vì users.id. Một sơ suất nhỏ, nhưng thú vị là nó không chỉ đơn giản là thêm id vào CTE.
Chúng tôi rất ấn tượng với cả hai câu trả lời trong phần này. Nó dễ dàng thêm rank và percent_rank với các đối số đúng mà không cần nói rõ. Các gợi ý của nó về cách giới hạn chỉ có 10 người chiến thắng cũng rất chính xác và hoạt động tốt.
Tối ưu hóa các truy vấn SQL với GPT-4
Tối ưu hóa các truy vấn SQL rất quan trọng để hoạt động dữ liệu hiệu quả, đặc biệt khi data warehouses tính phí dựa trên chi phí tính toán. GPT-4 có thể giúp tối ưu hóa truy vấn (các truy vấn tốn kém hoặc truy vấn mất quá nhiều thời gian để chạy) và đề xuất các phương án cải tiến.
Ví dụ, nếu được trình bày với một truy vấn không tối ưu như:
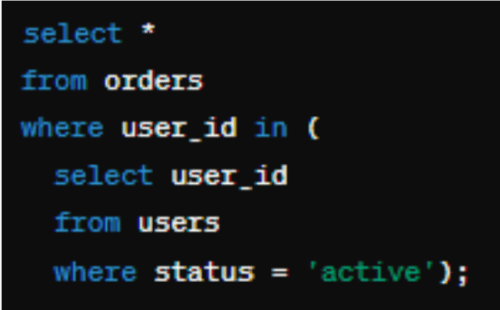
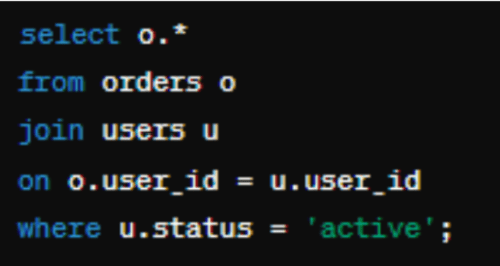
Cách tiếp cận AI-driven này không chỉ tăng tốc và tăng hiệu suất của các hoạt động cơ sở dữ liệu mà còn là một công cụ giáo dục, cung cấp thông tin về best practice và các chiến lược tối ưu hóa phổ biến. Nó có thể hữu ích cho các nhà phân tích mới vẫn đang học một số best practice này, và có thể tiết kiệm thời gian cho các nhà phân tích có kinh nghiệm hơn.
Một ví dụ thực sự về việc tối ưu hóa một truy vấn chi phí cao với AI
Chúng tôi đã xem xét các truy vấn chi phí cao trong trường hợp Snowflake (một nền tảng dữ liệu đám mây phù hợp với các SMEs) của phần mềm PopSQL và yêu cầu chatbot của OpenAI tối ưu hóa một số trong số chúng. Để xem câu trả lời sẽ như thế nào với ít câu hỏi, chúng tôi đã hỏi:
“Bạn có thể giúp tôi tối ưu hóa truy vấn này không? Nó rất tốn kém trong hóa đơn Snowflake của tôi.
[Ví dụ về một truy vấn SQL phức tạp ở đây]”
Và phản hồi rất hữu ích. Tất nhiên, việc triển khai các gợi ý này sẽ đòi hỏi sự làm việc nặng nhọc của một nhà phân tích, nhưng lượng thời gian tiết kiệm trong việc nghiên cứu sẽ khá lớn.
Truy vấn SQL bạn đã trình bày thực sự phức tạp và liên quan đến nhiều phép JOIN và CTE. Dưới đây là một số chiến lược để tối ưu hóa truy vấn trong Snowflake, cùng với một số gợi ý cụ thể:
- Giảm Phạm Vi Dữ Liệu:
- Chỉ truy vấn những gì bạn cần. Tôi thấy bạn sử dụng DISTINCT ở một số nơi. Nếu bạn có thể tự tin loại bỏ chúng, bạn có thể giảm thiểu tính toán.
- Giảm Độ Phức Tạp của Liên kết:
- Nếu có thể, hãy liên kết trên các cột có chỉ mục hoặc khóa chính.
- Bạn có một số lần chuyển từ ID nguyên thành văn bản để tham gia (cast(o.id as text)). Nếu việc kết nối có thể thực hiện trên các cột số nguyên, hãy tránh chuyển đổi vì nó tăng chi phí tính toán.
- Giới Hạn Số Bảng/CTEs:
- CTEs có thể tốt cho tính đọc dễ đọc, nhưng đôi khi sử dụng các truy vấn con hoặc bảng tạm thời có thể hiệu quả hơn, đặc biệt nếu CTE cùng được sử dụng ở nhiều nơi.
- Đồng Thời:
- Snowflake có thể song song hóa một số hoạt động. Nếu bạn có bảng cực kỳ lớn, hãy xem xét việc chia nhiệm vụ thành các nhiệm vụ nhỏ có thể chạy song song.
- Giảm Sử Dụng Hàm và Tính Toán Phức Tạp trong Mệnh Đề SELECT:
- Tôi thấy nhiều lần sử dụng parse_json và trim trong mệnh đề SELECT chính của bạn. Đây là các tính toán theo hàng và có thể tích lũy nếu bạn có hàng triệu hàng. Nếu các tính toán này có thể được thực hiện một lần và lưu trữ, điều này có thể hữu ích.
- Tối ưu Hóa Truy Vấn:
- Snowflake hỗ trợ phân vùng (họ gọi là “micro-partitioning”). Đảm bảo bảng của bạn sử dụng tính năng này để Snowflake có thể bỏ qua các phần không cần thiết của dữ liệu.
- CTE events_key chứa bộ lọc cho event_name. Nếu bạn có một chỉ mục trên event_name, điều này có thể làm tăng tốc quá trình lọc.
- Mệnh đề SELECT chính sử dụng một left join trên analytics.events_key. Nếu đây là cùng một bảng như dbt.events_key, hãy xem xét việc sử dụng lại CTE bạn đã xác định trước đó.
- Có các điều kiện lặp đi lặp lại như u.created_at >= current_date() – interval ‘3 months’. Điều này có thể được chuẩn hóa và sử dụng làm bộ lọc sớm trong quá trình (vì việc lọc sớm có thể giảm dữ liệu cần được xử lý ở phía dưới).
- Điều kiện và chuyển đổi (email as text) not like ‘%@gmail.%’ được sử dụng hai lần. Mặc dù nó không phải là một điều kiện tăng chi phí cao, nhưng hãy đảm bảo rằng việc lọc này thực sự cần thiết cho logic của truy vấn.
- Vật Lý Hóa Kết Quả Trung Gian:
- Nếu kết quả từ CTEs được sử dụng lại ở nhiều nơi hoặc truy vấn, hãy xem xét việc vật lý hóa kết quả vào một bảng tạm thời. Điều này có thể tránh việc tính toán lại.
- Tối Ưu Hóa Cấu Hình Snowflake:
- Xem xét cấu hình warehouse Snowflake của bạn. Sử dụng một warehouse lớn nếu cần thiết cho việc tính toán này, nhưng hãy nhớ rằng chi phí có thể tăng lên. Ngược lại, nếu warehouse của bạn quá lớn so với khối lượng công việc thông thường của bạn, bạn có thể đang trả quá nhiều.
- Xem Xét Kế Hoạch Thực Hiện:
- Snowflake cung cấp một kế hoạch thực hiện truy vấn. Hãy xem xét kế hoạch để xác định bất kỳ bước nào mất nhiều thời gian hoặc tài nguyên nhất định.
- Bảo Trì Định Kỳ:
- Thường xuyên chạy OPTIMIZE trên các bảng để duy trì hiệu suất tốt nhất.
Việc triển khai này sẽ đòi hỏi hiểu biết sâu rộng về dữ liệu của bạn, phân phối dữ liệu và nhu cầu chính xác của truy vấn. Hãy nhớ kiểm tra kỹ lưỡng mọi thay đổi để đảm bảo tính chính xác. Sau khi tối ưu hóa, cũng rất quan trọng để đo lường sự cải thiện về hiệu suất để định lượng tác động của các thay đổi của bạn.
Các nỗ lực thất bại trong việc dùng AI vào truy vấn dữ liệu SQL
Ví dụ trên đã hoạt động rất tốt, ngay cả khi chúng tôi trò chuyện một cách mơ hồ với OpenAI. Chúng tôi cũng thử nghiệm các luồng công việc khác nơi nó hoạt động cũng tốt như vậy. Tuy nhiên, có một số thất bại và thú vị thay, dường như những thất bại lớn nhất xảy ra ở những lĩnh vực mà các Data Analyst cũng thường gặp khó khăn.
AI gặp khó khăn nhất khi yêu cầu và ngữ cảnh về những gì cần thiết không đủ rõ ràng từ đầu. Ví dụ, trong ví dụ chính ở trên, khi chúng tôi yêu cầu created_at sau ngày 1/1/2020, nó loại trừ ngày 1/1 trong mệnh đề WHERE, điều này kỹ thuật là đúng, nhưng thực tế một nhà phân tích kinh nghiệm biết rằng doanh nghiệp có lẽ muốn bao gồm cả ngày 1/1.
Một ví dụ khác chúng tôi gặp trong một bài kiểm tra khác là khi chúng tôi yêu cầu truy vấn về số lượng đơn hàng hàng tuần. Nó tạo ra một truy vấn hoàn hảo, nhưng vì một số tuần không có đơn hàng trả lại, kết quả không phù hợp để tạo ra biểu đồ cho bảng trình bày. Trong trường hợp này, chúng tôi hỏi GPT-4 vấn đề là gì:
Tôi đã sử dụng truy vấn và nó đã hoạt động nhưng có những tuần bị thiếu… có chuyện gì vậy?
Nó ngay lập tức hiểu vấn đề là gì và đưa ra một truy vấn mới để sửa chữa. Điều đó có lẽ sẽ mất khá nhiều thời gian cho một data analyst không kinh nghiệm để tìm ra và giải quyết.
Tóm lại, khó có thể nói rằng chatbot bao giờ cũng thất bại. Chúng tôi đã cố gắng khiến nó gặp khó khăn và nó đã phát hiện ra vấn đề từ các lời nhắc của chúng tôi hoặc lấp đầy ngữ cảnh bị thiếu. Thách thức lớn nhất thực sự chỉ là đảm bảo bạn viết các lời nhắc hữu ích và cung cấp phản hồi đúng để hướng dẫn nó đi đúng hướng.
Khi có sai sót xảy ra, đó là lúc cực kỳ quan trọng để có một nhà phân tích SQL có kiến thức có thể nhận ra những sai sót đó và yêu cầu cập nhật truy vấn. Nếu là một fresher cố gắng tạo ra các truy vấn với AI, họ có thể làm tốt trong một thời gian ngắn, nhưng cuối cùng kết quả có thể không chính xác mà họ không thể nhận ra.
Nguồn tham khảo: POPSQL by Timescale
Data Coaching 1 on 1 – người bạn đồng hành giúp các bạn đạt mục tiêu apply vị trí Data Analyst thành công
Data Coaching 1 on 1 là dự án coaching của công ty TNHH UniGap – với sứ mệnh thu hẹp khoảng cách giữa trường đại học và nơi làm việc bằng phương pháp phù hợp, chi phí tối ưu và mục tiêu được cam kết.

Khoá Data Analyst Coaching 1 on 1 là khoá coaching giúp các bạn đang tự học Data Analyst đạt mục tiêu apply Data Analyst thành công trong 6 tháng. Đặc biệt phù hợp với các bạn dưới 27 tuổi, đang muốn tham gia ngành Data và cần có một đội ngũ thực chiến chuyên nghiệp đồng hành để giúp bạn đi nhanh hơn, cam kết đạt mục tiêu thành công.
Bạn có thể liên hệ để đặt lịch tư vấn miễn phí tại đây.
Data Coaching 1 on 1 – UniGap /Right mindset – True Success/
- Xem ngay Lộ trình học Data Analyst chuyển ngành thành công
- Tư vấn chuyển ngành Data Analyst miễn phí tại đây
- Tham gia Vietnam Data Analyst Forum – #1 Informative Group để học hỏi và chia sẻ kiến thức
- Cập nhật lịch khai giảng & chương trình ưu đãi tại Data Coaching 1 on 1 – UniGap

